Web Scraping
O que é? A raspagem de dados da web (em tradução livre) é o processo de extrair informações de websites. Isso é feito usando programas de computador ou scripts que acessam o código HTML de uma página da web e extraem os dados desejados de acordo com critérios específicos. Os…

O que é?
A raspagem de dados da web (em tradução livre) é o processo de extrair informações de websites. Isso é feito usando programas de computador ou scripts que acessam o código HTML de uma página da web e extraem os dados desejados de acordo com critérios específicos. Os dados coletados podem incluir texto, imagens, links, tabelas e muito mais.
Web scraping é uma ferramenta poderosa para coletar informações da web, e é usado em uma variedade de casos, como:
- Monitoramento de preços de produtos online.
- Coleta de dados para análise de mercado.
- Rastreamento de notícias e tendências.
- Coleta de informações de pesquisa acadêmica.
- Agregação de dados para comparação de produtos ou serviços.
- Extração de informações para treinamento de modelos de aprendizado de máquina.
Como funciona?
O web scraping funciona da seguinte forma:
- Requisição HTTP: Um script de web scraping inicia fazendo uma solicitação HTTP a uma página da web, geralmente usando uma biblioteca ou ferramenta específica, como o Python’s requests. Isso permite que o programa obtenha o conteúdo HTML da página.
- Análise HTML: Após a obtenção do conteúdo HTML da página, o script de web scraping analisa o código para identificar os elementos que contêm os dados desejados. Isso pode envolver a utilização de bibliotecas como BeautifulSoup (em Python) para navegar pelo código HTML de forma eficiente.
- Extração de dados: Depois de identificar os elementos HTML que contêm os dados necessários, o script de web scraping extrai esses dados. Isso pode incluir extrair texto de parágrafos, coletar informações de tabelas, buscar links ou até mesmo fazer download de imagens.
- Armazenamento ou processamento: Os dados extraídos podem ser armazenados em um arquivo, banco de dados ou processados diretamente pelo script para posterior análise, visualização ou uso em outros aplicativos.
Exemplo em Ruby
para escrever um script em ruby que faça a raspagem de dados na web vamos utilizar duas bibliotecas “Nokogiri” para a extração dos dados e “httparty” para fazer a requisição da pagina web.
gem install nokigiri
gem install httparty
depois de instaladas as dependências podemos começar a escrever nosso script scraper.rb
o proximo passo é fazer a requisição da pagina web utilizando o HTTParty
response = HTTParty.get("https://scrapeme.live/shop/")
logo após isso usar o Nokigiri para fazer o parse do documento HTML recebido
document = Nokogiri::HTML(response.body)
Agora basta identificar na pagina os elementos que deseja extrair, usando o modo de Inspecionar do navegador, neste exemplo vamos buscar cada pokemon da lista <li>
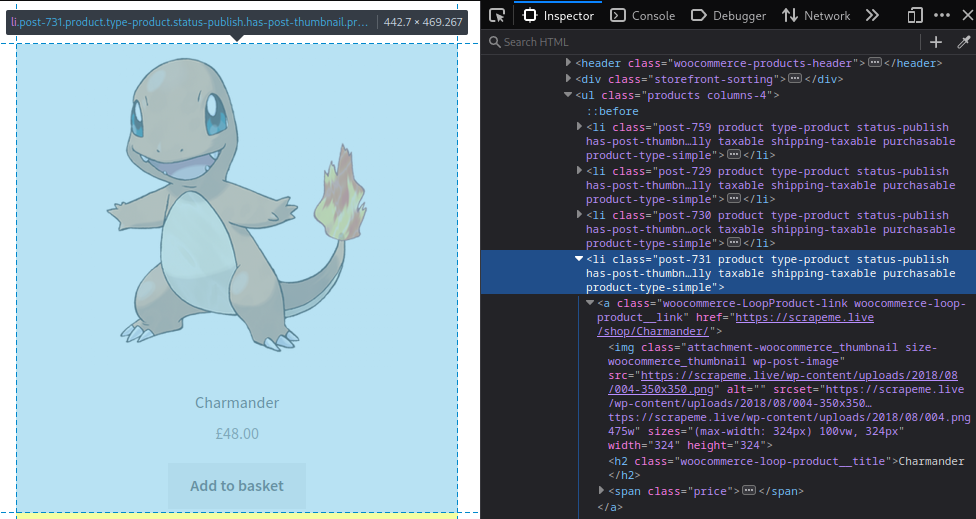
Primeiro criamos um objeto para armazenar os dados extraidos da página
PokemonProduct = Struct.new(:name, :price)
Selecionar todos os elementos <li> da pagina que tenham a classe “product”
html_products = document.css("li.product")
O metodo css() do Nokigiri permite selecionar elementos baseados no seletor CSS.
Por fim resta iterar pela lista dos <li> e raspar os dados relevantes para nós, no caso o nome que esta presente dentro de um <h2> do item da lista e o preço que esta na tag de <span>.
# inicialização da lista de pokemons
pokemon_list = []
html_products.each do |html_product|
nome = html_product.css('h2').text
preco = html_product.css('span').first.text
pokemon = PokemonProduct.new(nome, preco)
pokemon_list.push(pokemon)
end
Está pronto o script de raspagem!
Conclusão
Embora o web scraping possa ser uma ferramenta valiosa, ele deve ser usado com responsabilidade e respeito aos termos de serviço dos sites. Às vezes, os sites podem proibir a raspagem de seus dados ou impor restrições sobre como os dados podem ser usados. Portanto, é essencial entender e cumprir as políticas de cada site que você pretende raspar.