Gerenciando Múltiplos Bancos de Dados no Rails
Estratégias para gerenciar múltiplos bancos de dados em aplicações Rails, com foco específico na configuração Primary-Replica, no uso de gems como Makara e Distribute Reads, e no suporte nativo do Rails 6+ para múltiplos bancos de dados.
Tempo de leitura estimado: 15 a 20 minutos
Introdução
No cenário atual de desenvolvimento de aplicações web de alto desempenho, o gerenciamento eficiente de bancos de dados tornou-se um fator crítico para garantir a escalabilidade e a disponibilidade dos sistemas. À medida que o volume de dados e o tráfego de usuários aumentam, a arquitetura de banco de dados único pode se tornar um gargalo significativo, afetando o desempenho geral da aplicação.
O Ruby on Rails, como um dos frameworks mais populares para desenvolvimento web, tem evoluído continuamente para atender às demandas crescentes de aplicações. Uma evolução particularmente importante foi a introdução de suporte nativo para múltiplos bancos de dados a partir do Rails 6, permitindo que desenvolvedores implementem arquiteturas mais robustas e escaláveis.
Este artigo explora as estratégias para gerenciar múltiplos bancos de dados em aplicações Rails, com foco específico na configuração Primary-Replica, no uso de gems como Makara e Distribute Reads, e no suporte nativo do Rails 6+ para múltiplos bancos de dados.
Motivos para Implementar Primary-Replica em Aplicações Rails
Antes de mergulharmos nas implementações técnicas, é importante entender por que a arquitetura Primary-Replica é valiosa para aplicações Rails em crescimento:
1. Distribuição de Carga
Um dos principais benefícios de uma configuração Primary-Replica é a capacidade de distribuir a carga de trabalho do banco de dados. Operações de leitura, que geralmente constituem a maioria das interações com o banco de dados, podem ser direcionadas para os servidores Replica, enquanto as operações de escrita são enviadas exclusivamente para o servidor Primary.
2. Alta Disponibilidade
A implementação de múltiplos bancos de dados melhora significativamente a disponibilidade da aplicação. Se o servidor Primary falhar, um servidor Replica pode ser promovido para assumir esse papel, minimizando o tempo de inatividade.
3. Backup em Tempo Real
Os servidores Replica funcionam efetivamente como backups em tempo real do banco de dados Primary. Isso proporciona uma camada adicional de segurança contra perda de dados em caso de falhas no hardware ou no software.
4. Otimização de Consultas Analíticas
Consultas analíticas complexas e relatórios que exigem processamento intensivo podem ser direcionados para servidores Replica dedicados, evitando impactos no desempenho das operações cotidianas que ocorrem no servidor Primary.
5. Escalabilidade Horizontal
À medida que a demanda aumenta, mais servidores Replica podem ser adicionados para lidar com o aumento de tráfego de leitura, permitindo uma escalabilidade horizontal eficiente.
Usando Gems para Gerenciamento de Múltiplos Bancos de Dados
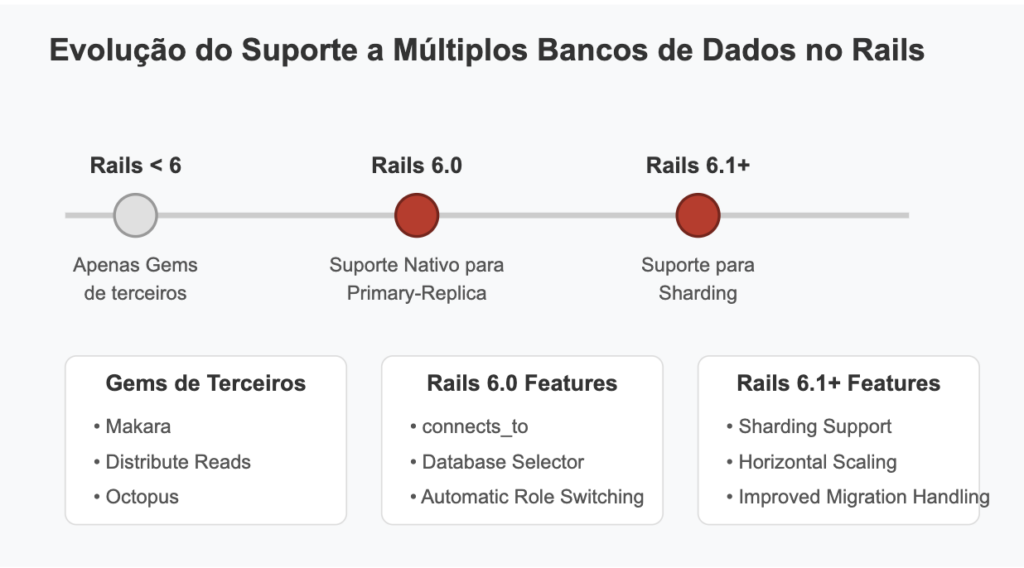
Antes do Rails 6, os desenvolvedores dependiam principalmente de gems de terceiros para implementar configurações de múltiplos bancos de dados. Duas gems particularmente populares são Makara e Distribute Reads.
Makara: Proxy para Múltiplos Bancos de Dados
Makara é uma gem desenvolvida pelo TaskRabbit que atua como um proxy de conexão para bancos de dados. Ela facilita a implementação de configurações Primary-Replica gerenciando automaticamente o roteamento de consultas.
Configuração Básica do Makara
A configuração do Makara em uma aplicação Rails envolve a modificação do arquivo database.yml:
default: &default
adapter: "postgresql_makara"
makara:
sticky: true
connections:
- role: primary
name: primary
database: myapp_production
host: primary-host
- role: replica
name: replica_1
database: myapp_production
host: replica-host-1
- role: replica
name: replica_2
database: myapp_production
host: replica-host-2
production:
<<: *defaultNesta configuração:
- O
adapteré definido comopostgresql_makara(também há suporte para MySQL). - A opção
stickygarante que, após uma operação de escrita, as consultas de leitura subsequentes sejam direcionadas para o Primary por um curto período, evitando problemas de consistência. - Cada conexão é configurada com um
role(primary ou replica) e outros parâmetros relevantes.
Uso do Makara em Código
O Makara funciona de forma transparente na maior parte do tempo, mas também oferece controle granular quando necessário:
# Forçar uso do primary para uma consulta específica
Makara::Context.with_primary do
User.find_by(email: params[:email])
end
# Forçar uso de replicas para um bloco de código
Makara::Context.with_replicas do
@users = User.all
@posts = Post.recent
endDistribute Reads: Simplificando o Roteamento de Consultas
Distribute Reads é outra gem popular que simplifica o processo de distribuição de consultas entre servidores Primary e Replica. Ela é particularmente útil quando usado em conjunto com a configuração de múltiplos bancos de dados do ActiveRecord.
Configuração do Distribute Reads
A configuração é bastante simples:
# Gemfile
gem 'distribute_reads'
# Inicialização
DistributeReads.by_default = true # opcional, para usar replicas por padrãoUso do Distribute Reads em Código
O Distribute Reads fornece uma API intuitiva para controlar o roteamento de consultas:
# Usar replica para um bloco de código
distribute_reads do
User.count # vai para o replica
end
# Com fallback para primary se o replica estiver indisponível
distribute_reads(failover: true) do
User.count
end
# Forçar primary para operações críticas
distribute_reads(primary: true) do
# todas as consultas vão para o primary
end
# Configurar um limite de tempo para uso do replica
distribute_reads(max_lag: 3) do
# usar replica apenas se estiver no máximo 3 segundos atrás do primary
endSuporte Nativo para Múltiplos Bancos de Dados no Rails 6+
O Rails 6, lançado em agosto de 2019, introduziu suporte nativo para múltiplos bancos de dados, reduzindo significativamente a necessidade de gems de terceiros para implementações básicas de Primary-Replica.
Configuração Básica no Rails 6+
A configuração de múltiplos bancos de dados no Rails 6+ é feita no arquivo database.yml:
production:
primary:
database: my_primary_database
username: root
password: <%= ENV['DATABASE_PASSWORD'] %>
adapter: mysql2
primary_replica:
database: my_primary_database
username: root_readonly
password: <%= ENV['DATABASE_READONLY_PASSWORD'] %>
adapter: mysql2
replica: true
animals:
database: my_animals_database
username: animals_user
password: <%= ENV['ANIMALS_DATABASE_PASSWORD'] %>
adapter: mysql2
migrations_paths: db/animals_migrate
animals_replica:
database: my_animals_database
username: animals_readonly
password: <%= ENV['ANIMALS_DATABASE_READONLY_PASSWORD'] %>
adapter: mysql2
replica: trueEsta configuração define dois conjuntos de bancos de dados: um para o banco de dados principal da aplicação (primary e primary_replica) e outro para um banco de dados específico para “animals” (animals e animals_replica).
Definindo Classes de Conexão
No Rails 6+, você precisa definir classes de conexão para cada grupo de banco de dados:
# app/models/application_record.rb
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary_replica }
end
# app/models/animal_record.rb
class AnimalRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :animals, reading: :animals_replica }
end
# Modelo usando a conexão padrão
class User < ApplicationRecord
end
# Modelo usando a conexão de animais
class Animal < AnimalRecord
endControle de Roteamento de Consultas
O Rails 6+ fornece métodos para controlar o roteamento de consultas entre os servidores Primary e Replica:
# Conectar a todas as réplicas para consultas de leitura no bloco
ActiveRecord::Base.connected_to(role: :reading) do
@users = User.all
@animals = Animal.all
end
# Conectar a um banco de dados específico para consultas de leitura
User.connected_to(role: :reading) do
User.first # vai para primary_replica
end
# Forçar uso do primary para operações de leitura
ActiveRecord::Base.connected_to(role: :writing) do
@users = User.all # vai para primary
endRecursos Avançados no Rails 6+
Automatic Role Switching
O Rails 6 introduziu a funcionalidade de troca automática de papel (role), que direciona automaticamente as consultas de leitura para replicas e as consultas de escrita para primary:
# config/application.rb
config.active_record.automatic_routing_to_primary = false
# Habilitação no middleware
Rails.application.config.middleware.insert_after ActiveRecord::QueryCache,
ActiveRecord::Middleware::DatabaseSelectorSharding
O Rails 6.1 expandiu o suporte para múltiplos bancos de dados com a introdução de suporte para sharding, permitindo a distribuição horizontal de dados entre vários bancos de dados:
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
default: { writing: :primary, reading: :primary_replica },
shard_one: { writing: :shard_one, reading: :shard_one_replica }
}
end
# Usar um shard específico
ActiveRecord::Base.connected_to(shard: :shard_one) do
# Operações no shard_one
endEstratégias de Migração e Considerações de Implementação
Migração Gradual para Múltiplos Bancos de Dados
Ao migrar de uma arquitetura de banco de dados único para múltiplos bancos de dados, é recomendável adotar uma abordagem gradual:
1. Análise de Padrões de Acesso: Inicie analisando os padrões de acesso ao banco de dados para identificar quais modelos são predominantemente de leitura versus escrita.
2. Implementação Seletiva: Comece implementando a funcionalidade de múltiplos bancos de dados para modelos específicos que beneficiariam mais dessa arquitetura.
3. Monitoramento e Ajuste: Monitore de perto o desempenho e faça ajustes conforme necessário antes de expandir para mais modelos.
Considerações de Latência e Replicação
Ao trabalhar com configurações Primary-Replica, é importante considerar a latência de replicação:
# Com Distribute Reads
distribute_reads(max_lag: 5.seconds) do
# Consultas aqui usarão o replica apenas se
# estiver no máximo 5 segundos atrás do primary
end
# No Rails 6+
Rails.application.config.active_record.database_selector = { delay: 5.seconds }Conclusão
O gerenciamento eficaz de múltiplos bancos de dados é essencial para a escalabilidade de aplicações Rails à medida que crescem em tráfego e volume de dados. Embora gems como Makara e Distribute Reads tenham sido fundamentais antes do Rails 6, o suporte nativo para múltiplos bancos de dados a partir do Rails 6 simplificou significativamente a implementação de arquiteturas Primary-Replica.
A escolha entre usar gems ou o suporte nativo dependerá das necessidades específicas da sua aplicação:
Para aplicações em versões anteriores ao Rails 6, Makara e Distribute Reads continuam sendo excelentes opções.
Para novas aplicações ou aquelas migradas para o Rails 6+, o suporte nativo oferece uma solução mais integrada e mantida oficialmente.
Independentemente da abordagem escolhida, a implementação de uma arquitetura de múltiplos bancos de dados pode trazer benefícios significativos em termos de desempenho, disponibilidade e escalabilidade para aplicações Rails em crescimento.
À medida que o ecossistema Rails continua a evoluir, podemos esperar melhorias adicionais no suporte para arquiteturas de banco de dados mais complexas, permitindo que desenvolvedores construam aplicações ainda mais robustas e escaláveis.
Referências
1. Documentação oficial do Rails sobre Múltiplos Bancos de Dados