Índices no PostgreSQL com Ruby on Rails
Imagine que você está procurando uma palavra específica em um dicionário e em vez de folhear página por página até encontrar, você usa o índice alfabético, que aponta rapidamente onde a palavra está, economizando tempo e esforço. Em bancos de dados relacionais, como o PostgreSQL, o conceito de índice funciona…
Imagine que você está procurando uma palavra específica em um dicionário e em vez de folhear página por página até encontrar, você usa o índice alfabético, que aponta rapidamente onde a palavra está, economizando tempo e esforço.
Em bancos de dados relacionais, como o PostgreSQL, o conceito de índice funciona de forma semelhante. Um índice é uma estrutura auxiliar criada para acelerar consultas, armazenando de forma ordenada os valores da coluna indexada, junto com uma informação de onde está o registro dentro da tabela. Ele atua como um atalho para o banco encontrar os registros que atendam a determinado critério de busca, evitando a leitura linha por linha de toda a tabela, o chamado table scan.
Assim, quando você faz uma busca, por exemplo:
SELECT * FROM clientes WHERE email = '[email protected]';O banco primeiro consulta o índice para verificar se aquele e-mail existe e caso exista ele já sabe onde ir na tabela para buscar o registro correspondente sem precisar olhar as outras linhas. Na prática, é como se o PostgreSQL pensasse: “Esse cliente com esse e-mail está na página X, linha Y.”.
Tipos de índices
O PostgreSQL oferece diferentes tipos de índices, sendo eles:
- B-tree (árvore B): O índice mais usado no dia a dia, indicado para buscas por igualdade, ordenações e filtros simples.
- Hash: Focado apenas em buscas por igualdade, mas raramente usado porque o B-tree costuma ser suficiente.
- GIN: Indicado para buscas dentro de arrays, JSON ou para implementar busca textual.
- GiST: Útil para consultas mais complexas, como geolocalização ou buscas por similaridade.
- BRIN: Recomendado para tabelas gigantes, onde os dados estão organizados por faixa (como logs com data/hora).
Nesse artigo, vamos focar no tipo mais comum, o índice B-tree.
Quando utilizar índices
Os principais cenários são:
- A coluna é muito usada em filtros (WHERE):
Consultas que buscam registros com base em uma coluna específica, como e-mail, CPF ou status. - A coluna aparece com frequência em JOINs:
Quando as tabelas usam campos como chaves estrangeiras (cliente_id, usuario_id, etc.). Ter um índice nessas colunas facilita e agiliza o processo de junção entre tabelas. - Muitas consultas com ordenação (ORDER BY):
Se as consultas ordenam os resultados com base em uma coluna específica (como data de criação, por exemplo). O PostgreSQL pode usar o índice para devolver os resultados já na ordem certa, evitando o custo de ordenar os dados depois. - A coluna é usada em buscas por intervalo (BETWEEN, maior que, menor que):
Quando as consultas precisam localizar registros dentro de um intervalo de valores, como um período de datas ou um intervalo numérico.
Pontos de atenção
Apesar dos benefícios, criar índices sem planejamento pode trazer problemas de performance e manutenção. Alguns cuidados importantes:
- Impacto na criação do índice:
Ao criar um índice, o banco de dados precisa ler toda a tabela para construir a estrutura, o que pode bloquear gravações temporariamente. - Impacto nas operações de escrita:
Cada vez que um registro é inserido, atualizado ou excluído, o PostgreSQL precisa atualizar todos os índices relacionados àquela tabela. Isso pode deixar operações de escrita mais lentas. - Consumo de espaço em disco:
Índices ocupam espaço físico. Quanto mais índices você cria, mais espaço o banco de dados vai utilizar. - Índices em colunas com pouca variedade de valores:
Criar índices em colunas que possuem poucos valores diferentes, como campos booleanos, geralmente não traz ganho de performance e pode até piorar. - Quantidade excessiva de índices:
Ter muitos índices na mesma tabela pode confundir o otimizador de consultas do PostgreSQL e gerar escolhas ruins no algoritmo de seleção. - Manutenção dos índices:
Índices também precisam ser monitorados e, em alguns casos, reindexados ou analisados ao longo do tempo para manter a eficiência.
Aplicando índices com PostgreSQL e Ruby on Rails
Cenário 1: Filtro por status na tabela orders (sem índice):

A consulta foi realizada percorrendo toda a tabela (35 mil linhas) e retornou 8797 linhas que satisfaziam a condição desejada em 3,4 milissegundos:

Com a criação de um índice na coluna status:
CREATE INDEX index_orders_on_status ON orders (status);
A consulta foi executada utilizando o plano escolhido automaticamente pelo PostgreSQL e também retornou 8797 linhas que satisfaziam a condição desejada, porém em 1,4 milissegundos:

No Rails, a criação do índice poderia ser feita de forma mais amigável através de uma migração:
class AddIndexToOdersStatus < ActiveRecord::Migration[7.2]
def change
add_index :orders, :status
end
endAo efetivar as alterações no banco de dados, no schema.rb teríamos uma nova linha:
t.index ["status"], name: "index_orders_on_status"E o resultado da criação do índice seria o mesmo do feito diretamente pelo PostregSQL.
Cenário 2: Ordenação por name na tabela customers (sem índice):

A ordenação de 186 mil linhas foi realizada em 85,5 milissegundos:

Com a criação de um índice na coluna name:
CREATE INDEX index_customers_on_name ON customers (name);
A consulta foi executada em 22,5 milissegundos:

Com Rails poderia ser feito da mesma forma como no exemplo anterior:
class AddIndexToCustomersName < ActiveRecord::Migration[7.2]
def change
add_index :customers, :name
end
endt.index ["name"], name: "index_customers_on_name"Cenário 3: Consulta de orders por customer_id
No Rails, ao criar uma nova tabela com uma referência para outra tabela (usando t.references), um índice para a coluna de chave estrangeira é adicionado:
class CreateOrders < ActiveRecord::Migration[7.2]
def change
create_table :orders do |t|
t.references :customer, foreign_key: true, type: :uuid
t.integer :status, default: 0
t.decimal :total_value, precision: 15, scale: 2
t.timestamps
end
end
endNo schema.rb teremos a seguinte linha:
t.index ["customer_id"], name: "index_orders_on_customer_id"E o processo de criação da tabela no banco de dados fará algo como:
CREATE INDEX index_orders_on_customer_id ON orders (customer_id);Com o índice, a consulta foi realizada em 0,06 milissegundos e encontrou 2 linhas:

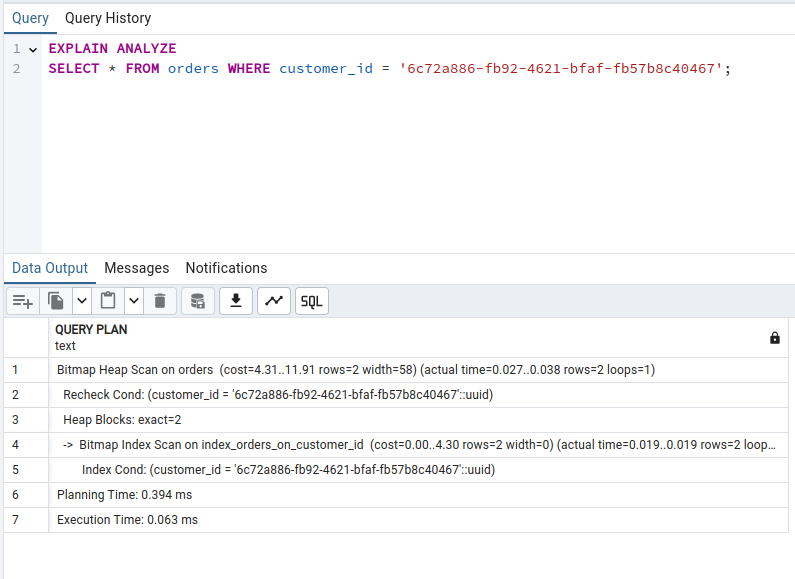
A mesma query sem o índice também retornou 2 linhas, no entanto, foi realizada em 5,8 milissegundos:

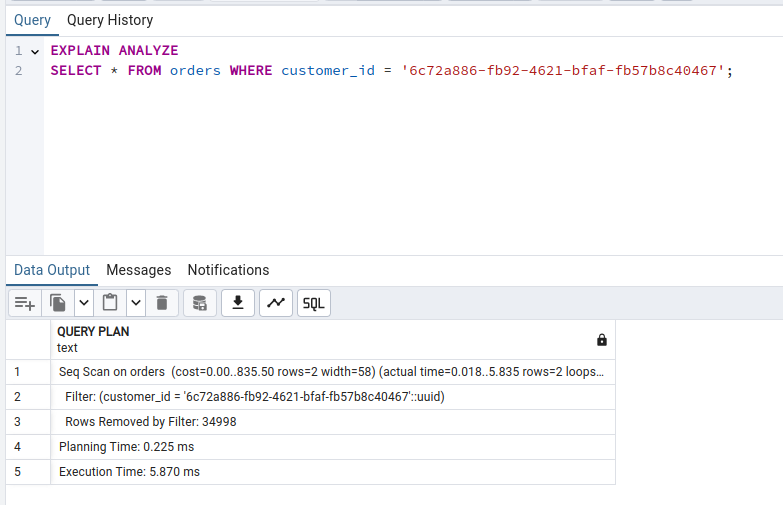
Conclusão
Índices são fundamentais para melhorar a performance das consultas no PostgreSQL. Quando aplicados de forma estratégica podem reduzir drasticamente o tempo de execução e tornar o acesso aos dados muito mais eficiente. Por outro lado, criar índices em excesso ou em colunas pouco relevantes pode gerar impactos negativos em gravações e no consumo de espaço. Por isso, é sempre importante analisar o comportamento das consultas e criar índices que realmente tragam benefícios.
Referências
- https://www.postgresql.org/docs/current/indexes.html
- https://pt.wikibooks.org/wiki/PostgreSQL_Pr%C3%A1tico/DDL/%C3%8Dndices,_Tipos_de_Dados_e_Integridade_Referencial